
从稀疏连接性、权重共享、动态权重进一步探究Local Attention。
论文名称:Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight
作者:Qi Han1,Zejia Fan,Qi Dai,Lei Sun,Ming-Ming Cheng,Jiaying Liu,Jingdong Wang
介绍
本文的主要成果发现(finding)如下:
Local Transformer采用的Local Attention利用了现有的正则化方案(regularization schemes)、稀疏连接(sparse connectivity )、权重共享(weight sharing)以及动态权重预测(dynamic weight prediction),在不需要额外增加模型复杂度和训练数据的情况下增加性能;
局部注意力(Local Attention)与(动态)深度卷积((dynamic )depth-wise convolution)在稀疏连接性上相似,在权重共享和动态权重预测上不同。
实验结果表明,局部注意力和(动态)深度卷积所采用的正则化形式和动态权重预测方案具有相似的性能。
此外,提出了一个关系图来联系卷积和注意力,同时开发了基于MLP的方法。
关系图表明,这些方法本质上利用了不同的稀疏连接和权重共享模式,可以选择使用动态权重预测进行模型正则化。
Understanding Local Attention

上图分别表示了(a)convolution,(b) global attention and spatial mixing MLP,(c) local attention and depth-wise convolution, (d) point-wise MLP or convolution, (e) MLP (fully-connected layer)的连接模式。
接下来将对其进行介绍——
Sparse Connectivity, Weight Sharing, and Dynamic Weight
本节将简要介绍两种正则化形式:稀疏连接和权重共享,以及动态权重,和它们的优点,并使用这三种形式来分析局部注意力,将其与深度卷积联系起来。
稀疏连接:稀疏连接意味着某些输出和某些输入之间并没有联系,它在不减少神经元的情况下,降低了模型的复杂度。
权重共享:权重共享表示某些连接权重相等,它减少了模型的参数量,增加了网络的大小,并且不需要增加相应的训练数据。
动态权重:动态权重指的是为每个实例学习特定的连接权重,它旨在增加模型表达能力,如果将学习的连接权重视为隐藏变量,则可以将动态权重视为引入二阶操作(该观点在Involution和VOLO中都有所表现,将在后面进行讨论),从而提高网络的能力。
Local Attention
Vision Transformer通过重复注意力层和后续的前馈层形成一个网络,而Local Vision Transformer,采用局部注意力层,将空间划分为一组小窗口,在每个窗口内同时计算自注意力,以提高内存和计算效率。
多头局部自注意力最终可写作如下形式:
其中i表示当前位置,j表示整个窗口中的所有位置,即表示一个窗口中像素的总数(下同)。
Properties
Local Attention是一个具有动态权重计算的channel-wise和spatially-locally的连接层。
其聚集信息的过程可以等价地写成:
表示逐元素相乘,表示权重向量,从中获得。
稀疏连接:
Local Attention在空间上是稀疏的,每个位置只与一个小窗口中的其他位置连接,并且通道间不存在连接。
上式中的表示给定注意力权重,每个输出的元素,比如(第d个通道中的第i个位置),是依赖于同个通道同一窗口中的其他输入元素,而与其他通道上的元素无关。
权重共享:
权重在每个通道间共享。
对于单头注意力,所有都是相同的,;
对于多头注意力,被划分为M个子向量,有.
动态权重:
权重是动态地从查询向量和窗口中的键向量生成的(点积和Softmax),可以写成如下形式:
每个权重都可能包含所有通道的信息,并且充当跨通道信息交流的桥梁,因为其在通道间共享权重,所以每个权重都可能学习到这些通道的信息,这一定程度上起到了跨通道交流的作用
集合表示(Set representation):
每个query对应的key和value被表示为一个集合,这就导致其存在的位置关系没有被利用,但是这可以被位置嵌入,或是学习一个相对位置嵌入所弥补。
Connection to Depth-Wise Convolution
深度卷积对每个通道都使用一个单独的卷积核,输出时并不会求和,是分组卷积的极致表示,但是这意味着通道之间没有任何信息交流,可以写成如下形式:
将Local Attention和深度卷积进行对比:
相似性:二者在稀疏连接上具有相似性:No Connection Across Channels,每个位置仅与同通道上的窗口其他位置相连接。
差异性:
权重共享:深度卷积只在空间上共享权重,而Local Attention跨通道共享权重;
连接权重的性质:对于深度卷积来说,连接权重是静态的,被学习表示为模型的参数,而对于Local Attention,其连接权重是动态的,其为每一个实例(像素)单独生成;
深度卷积也可以从动态权重中受益——主要分为两种,一是学习一致的动态权重,二是为每个实例动态生成权重,将在后面进行介绍;
窗口表示:深度卷积天然地保留了位置信息,而Local Attention则需要使用位置嵌入来弥补位置信息的丢失。
关系图
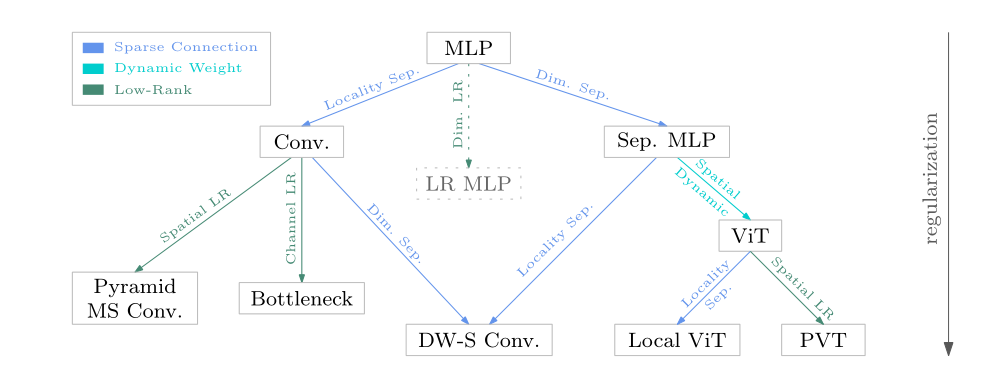
提出了一个关系图,其包含了三种正则化方法——稀疏连接、动态权重和低秩。
- MLP在空间上稀疏连接便得到了标准卷积:
- 在空间上低秩化便能得到金字塔、多尺度卷积;
- 在通道上低秩化便得到了Bottleneck;
- 在通道上稀疏连接又能得到深度可分离卷积;
- MLP在维度上稀疏连接便得到了separable MLP:
- 在空间上稀疏连接便能得到深度可分离卷积;
- 在空间上实现动态权重得到ViT:
- 在空间上稀疏连接便得到Local ViT;
- 在空间上低秩化便得到PVT;
Experimental Study
与Swin Transformer进行对比,在ImageNet图像分类,COCO目标检测和ADE语义分割上进行了实验。
Architectures
将Swin-T和Swin-B中的Local Attention替换为了深度卷积,所有的线性映射层都替换为卷积层,同时建立了动态权重版本的深度卷积,该版本使用类似于SENet的技术生成一致动态权重。
Datasets and Implementation Details
看论文
Main Results
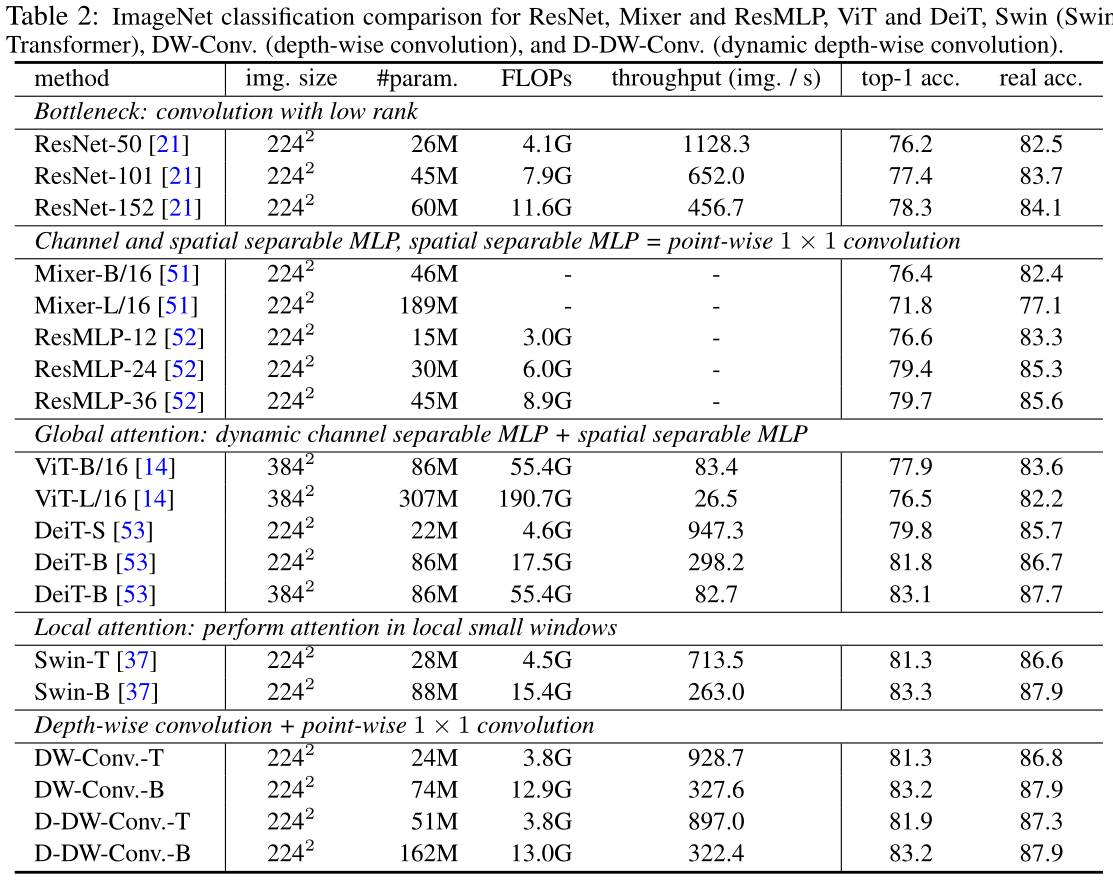
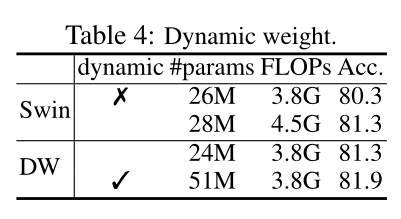
ImageNet classification:深度卷积版本的参数量和计算量都下降了约15%,动态版本的参数量大量上升,但复杂度几乎相同,性能几乎持平,同时比较了其他方法的性能
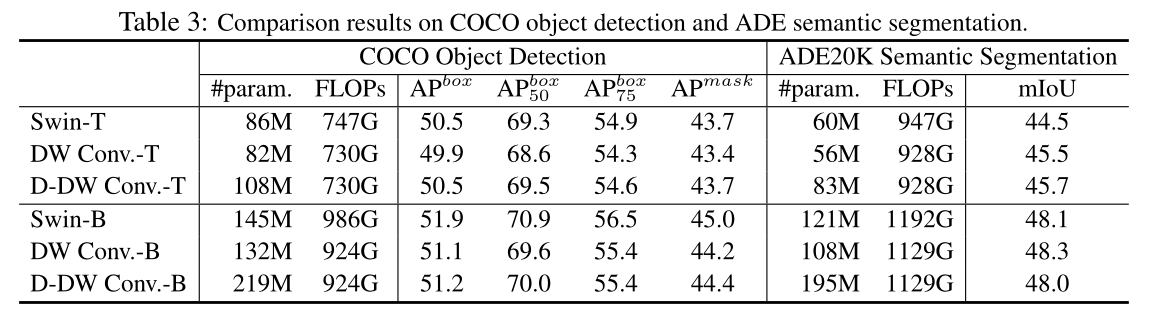
COCO object detection、ADE Semantic Segmentation:
Additional Studies
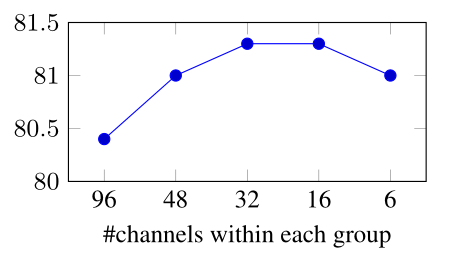
Weight sharing:研究了在通道间共享权重对深度卷积和Swin Transformer的影响
Dynamic weight:
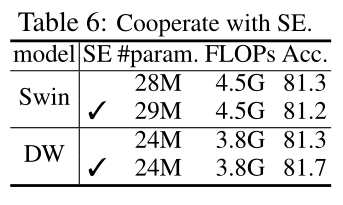
Cooperating with SE:SE是一个参数和计算效率较高的动态模块,DW可以从中受益,但是本身已是动态模块的Swin出现了掉点的情况。
更多看论文
Dynamic Weight
动态权重主要有两种类型——学习一致的权重(homogeneous connection weight),为每个位置或者区域生成不同的权重。
第一种学习一致的权重,比如Dynamic Convolution,或者最经典的SENet,实际上也是一种动态权重。
其主要特点是对于每一个输入(特征图)给出唯一的权重,该权重在空间上共享。
第二种为每个实例(位置、区域)生成不同的权重,比如GENet、Involution、VOLO以及Vision Transformer。
其主要特点是对于每一个输入(某个位置或者区域)生成唯一的权重,该权重仅在该位置或者区域生效。
本文采用了第一种权重生成方法,
class DynamicDWConv(nn.Module):
def __init__(self, dim, kernel_size, bias=True, stride=1, padding=1, groups=1, reduction=4):
super().__init__()
self.dim = dim
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.groups = groups
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.conv1 = nn.Conv2d(dim, dim // reduction, 1, bias=False)
self.bn = build_norm_layer(norm_cfg_global, dim // reduction)[1]
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(dim // reduction, dim * kernel_size * kernel_size, 1)
if bias:
self.bias = nn.Parameter(torch.zeros(dim))
else:
self.bias = None
def forward(self, x):
b, c, h, w = x.shape
weight = self.conv2(self.relu(self.bn(self.conv1(self.pool(x)))))
weight = weight.view(b * self.dim, 1, self.kernel_size, self.kernel_size)
x = F.conv2d(x.reshape(1, -1, h, w), weight, self.bias.repeat(b), stride=self.stride, padding=self.padding, groups=b * self.groups)
x = x.view(b, c, x.shape[-2], x.shape[-1])
return x
VOLO:OutLook Attention
VOLO也是一种Local Attention,并且性能表现优异,将其中的Local Attention的部分分别替换为self attention和深度卷积,可得到如下结果:
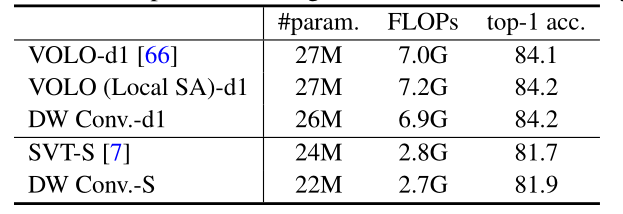
同时替换了了SVT中的Local Attention部分,结果都是有所增加的。